Demand Suppression

Labels: alienation, cartoon, negative effects, uplift
posted by njr at 09:13 PERMALINK
![]()
On control groups, lift, direct marketing and analytics . . . mainly
Labels: alienation, cartoon, negative effects, uplift
posted by njr at 09:13 PERMALINK
![]()
In The Fundamental Campaign Segmentation I introduced a theoretical classification of customers according to how their behaviour is affected by a marketing action such as a mailshot. Today I want to look at a softer, more practical version of that segmentation, and use this to look at the rather serious shortcomings of both response models and penetration models.
The “hard” version of the segmentation that I talked about previously depended on knowing whether each customer buys if treated, and also whether she buys if not treated. Such knowledge allows us to talk of “Persuadables”, who buy only if treated, “Sure Things”,1 who buy either way, “Lost Causes”, who don't buy either way, and “Boomerangs”, who only buy if not treated. But of course, we can never know which segment anyone falls into, because we can't both treat and not treat someone.
What we can do more easily, both conceptually and in practice, is to estimate the probability of someone's purchasing when treated, and the corresponding probability of purchasing when not treated. This suggests a “soft” version of the Fundamental Segmentation as follows:
![The soft form of the Fundamental Campaign Segmentation for Demand Generation. The horizontal axis shows probability of purchase if not treated, while the vertical axis shows the probability of purchase if treated. The diagram shows four segments,
- Persuadables (top left) [more likely to purchase if treated];
markedly when treated;
- Lost Causes (bottom left), [unlikely to purchase];
- Sure Things (top right), [likely to purchase]; and
- Boomerangs (bottom right), [more likely to purchase if not treated].](http://farm1.static.flickr.com/145/410223243_8bc2562eb9_o.png)
The horizontal axis shows the probability of purchase if the customer is not treated, while the vertical axis shows the corresponding probability under treatment. A customer who is completely unaffected by the campaign will lie along the centre of the white stripe (the “leading diagonal”). The more positively the action affects the customer's purchase probability, the further toward the top left she will lie on the graph, and conversely, if the action actually reduces her probability of purchase, she will lie further towards the bottom right corner.
Given this framework, it is natural to define soft versions of the segments with boundaries parallel and perpendicular to the diagonal representing “completely unaffected” customers. The key point is that our returns are proportional to the distance from that diagonal (which represents the uplift). Distance from the diagonal towards the top left corner quantifies positive incremental impact (extra sales generated), while distance below and to right represents negative effects (destruction of incremental sales).
Let's look at penetration models through the clarifying lens of our Fundamental Segmentation in its “soft” form. Penetration models simply look at the proportion of people who purchase a product without any particular stimulation. In other words, they model purchase probability without treatment—exactly what we are plotting on the horizontal axis. So let's look at what happens if we target some campaign action on the basis of such a penetration model. The usual practice is to target everyone with a “propensity” above some cutoff, i.e. everyone to the right of some vertical line on the graph. One such is shown on the diagram below.
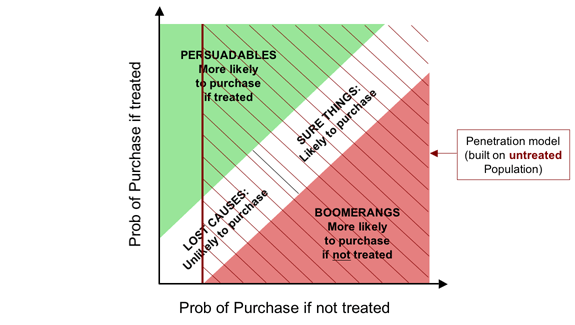
As the diagram makes fairly plain, the problem with penetration models is that they tend to target all of the Boomerangs, thereby actively driving away business, as well as wastefully picking up all of the Sure Things, who would buy anyway. Perhaps more surprisingly, they don't even encourage us to target all of the Persuadables. This is because penetration models are built on an untreated population and have absolutely no information about what would happen if we stimulated these customers.
Clearly, if our goal is to maximize the return on a direct marketing campaign, the last thing we want to do is target on the basis of a penetration model.
So if penetration models don't look to be doing anything very close to what we want, what about traditional “response” models? The difference between a penetration model and a response model is that where the former is built on an untreated population, the latter is built on a treated population. Assuming, again, that some threshold value is picked for probability of purchase if treated, the impact of targeting with a response model is shown below.
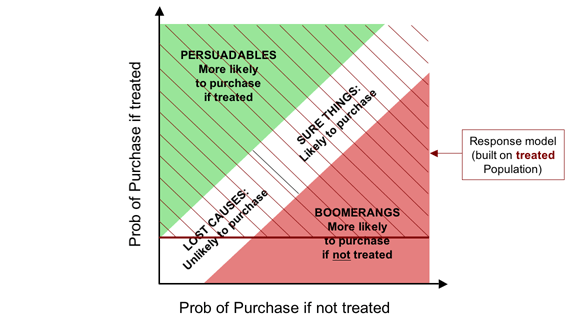
The good news is that the “response” model (so called) does something closer to what we want, while still being far from ideal. On the positive side, it does capture all the Persuadables—the people whose purchase probability is materially increased by our marketing action. On the less positive side, it also targets all the Sure Things (who would have bought anyway) and a good proportion of the Boomerangs, for whom our efforts are counterproductive.
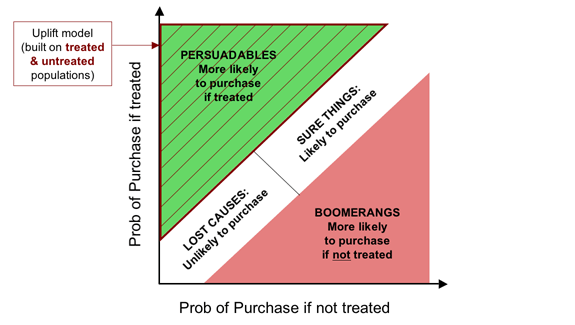
The problem with both penetration models and response models is that they misdirect our targeting efforts by modelling the wrong thing. If our goal is to maximize the incremental business we generate, we would like to target the Persuadables and no one else. If we model uplift—the increase in purchase probability resulting from treatment—this is exactly what we are able to do, regardless of exactly how much “uplift” we require to break even. This is illustrated below.
If our goal is retention, the story is similar, but with some intriguing (and perhaps unexpected) differences.
The soft version of the Fundamental Campaign segmentation for retention presented previously is exactly as you would expect, and is shown here.
![The soft form of the Fundamental Campaign Segmentation for Retention. The horizontal axis shows probability of leaving if not treated, while the vertical axis shows the probability of leaving if treated. The diagram shows four segments,
- Persuadables (bottom right) [more likely to stay if treated];
markedly when treated;
- Lost Causes (top right), [unlikely to stay];
- Sure Things (bottom left), [likely to leave]; and
- Sleeping Dogs (top left), [more likely to leave if treated].](http://farm1.static.flickr.com/120/410223480_15f744a931_o.png)
The standard approach to model-driven targeting of retention activity is to model the probability that a customer is going to leave and then to target valuable customers thought it identifies as having an unacceptably high risk of leaving.
For applications such as cross-selling, we saw that a response model (built on a treated population) was a significant advance on a penetration model (which is built on a non-treated population). As we shall see, this pattern is reversed for retention.
If we have an established retention programme, the likelihood is that most, if not all, high-risk customers will be subject to retention activity. As a result, when we build our attrition models (churn models), these will usually be based on a population that is largely or entirely made up of customers who have been (at least in the high-risk segments). We can see the effect of targeting on this basis on the overlay below.
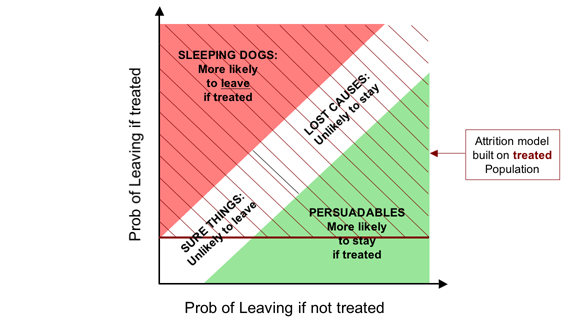
It might at first seem strange that a retention model built on a treated population has exactly analogous failings to a penetration model for demand stimulation: it misses some of the Persuadables, (customers who can be saved, or at least made more likely to stay, by our retention activity) while targeting all Sleeping Dogs (who are driven away by it) as well as many who will go regardless of our actions (the Lost Causes).
As the next overlay shows, if we are going to target on the basis of probability of leaving, it should at least be the probability of leaving if we do nothing. Ironically, this is easiest to achieve if we have a new retention programme, and therefore an untreated population.
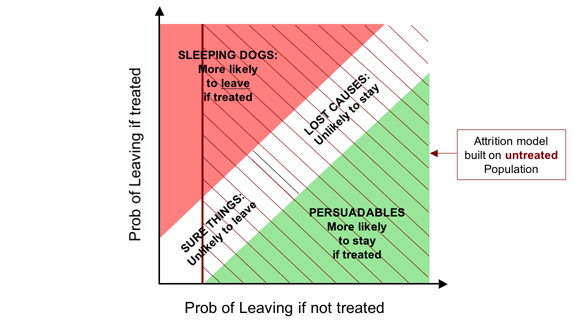
So while for demand generation, a response model built on a treated population is somewhat better than a penetration model built on a treated population, this situation is reversed for retention activity: we are better off targeting people based on their probability of leaving if untreated than the corresponding probability when subject to a retention action. And it is particularly important to get this right for retention because most retention activity actually triggers defection for a significant minority of those we try to save (and occasionally a majority).
Needless to say, once again the real solution is to target based on that which actually affects campaign profitability, the incremental effectiveness of the action, or the uplift. We can see this clearly on our final diagram.
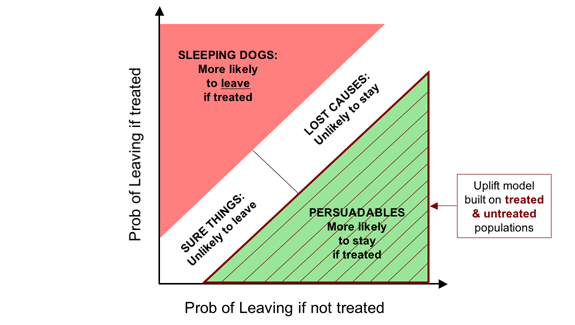
As I said before, it is important that we model that which is important, and if our goal is to maximize the incremental impact of our campaigns, that is uplift.
1In fact, the name I used for Sure Things in the previous post was “Dead Certs”, but it seems that is a bit of UK-centric idiom (“cert” being an abbreviation of certain); Sure Things appears a bit more international, i.e. American. ↩
posted by njr at 08:43 PERMALINK
![]()